Our vision is to empower everyone to materialize their 3d art. That's why we built Meshy-1, a fast generative AI for 3D, empowering content creators to convert text and images into captivating 3d models online in just under a minute.
In this blog, we're excited to unveil the story behind Meshy-1 and its capabilities. Prepare to be amazed!
Why is GenAI for 3D important (and hard)?
The surge in 3D interactive content, especially in the game, film, and XR industries, has spiked the demand for 3D models. Expert creators face lengthy production times, while casual creators struggle with complex tools like Maya or Blender. This gap, amplified by barriers of cost and complexity, calls for a solution.
Now is the pivotal moment. With the unveiling of Apple's Vision Pro and Meta introducing the Quest 3, coupled with the rapid progression of generative AI technology and a burgeoning gaming market, the collective anticipation for a groundbreaking AI 3D generator is palpable and ripe for realization.

In this thrilling era of generative AI, numerous powerful products are emerging across different modalities. For instance, we see ChatGPT for text, Midjourney for images, and Runway for videos.
While it may seem logical to presume 3D generation as the forthcoming stride, intriguingly, there is no definitive leader in this sphere, primarily because the recipe for crafting an effortless-to-use product remains undiscovered. Why is this the case?
My journey through both academia and industry [1] provides a lens into the reasons behind this.
Challenge 1: The trade-off between quality and speed. Presently, there are two predominant approaches within the realm of 3D GenAI:
- 2D Lifting: Elevating 2D generative models (such as Stable Diffusion) to 3D, utilizing iterative optimization techniques applied to structures like NeRFs. These methods use lots of 2D data and can make various good-quality 3D models, but it's slow and can take hours even on fast GPUs like the RTX 3080.
- 3D Diffusion: This approach significantly trims the generation time to less than 1 minute per model. Because there's not much 3D training data available, models made this way often lack good quality.
 Current methods are either too slow or lack the desired quality, hindering the development of an effective product. Meshy aims to be both fast and high-quality.
Current methods are either too slow or lack the desired quality, hindering the development of an effective product. Meshy aims to be both fast and high-quality.
That's why there aren't many 3D GenAI products out there. Using 3D diffusion results in low quality, while 2D lifting leads to long wait times for users and high server costs. Our team worked hard to combine the benefits of the two approaches and beat the trade-off between quality and speed, creating a product that lets users turn text or images into good 3d models in under a minute.

Challenge 2: The chasm between academic innovations and user needs. A user-centric product transcends mere algorithms and neural network weights; it necessitates intuitive user interfaces and seamless integrations with prevalent tools like Unity and Blender. Moreover, it must offer manageable polycounts suitable for mobile gaming and provide effective content/style control to authentically materialize user ideas. While productization isn't rocket science, it does require profound product insights and a deep understanding of the CG industry to develop. [2]
Meshy-1: 3D GenAI Made Fast and Superb
As previously stated, if the generation process spans hours, it becomes challenging to create a product that scales to even hundreds of users. So as a maker, it's urgent to fist solve the speed issue.
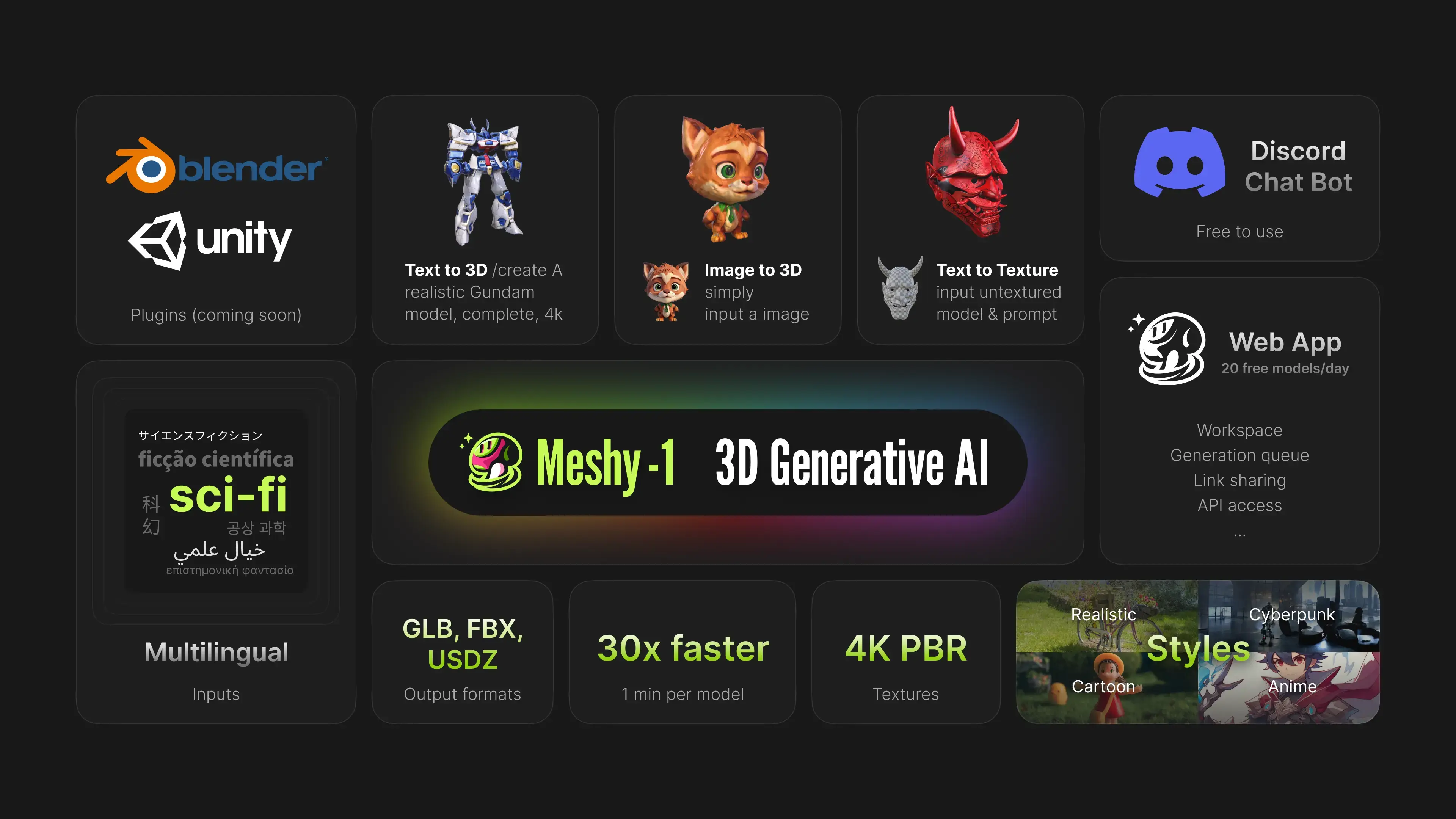
Introducing Meshy-1, a fast 3D generative AI, empowering content creators to transform text and images into captivating 3D models in just under a minute. Meshy-1 has three easy-to-use modes:
- Text to 3D: Words in, 3D models out
- Image to 3D: Pictures provided, 3D models produced
- Text to Texture: Texture your models with simple text descriptions [3]
All three modes work fast and give you results in under 60 seconds.
A fully AI-generated scene. Every model in this scene is generated using Meshy-1 Text to 3D.Building on a common Meshy-1 foundation, the three modes share common features that were previously not available in existing products:
30x faster. Existing products can leave users waiting for hours, and we believe that's unacceptable. Meshy-1 revolutionizes this process by delivering results in under a minute[4]. Not only does this enhance user experience and productivity, but Meshy-1's remarkable efficiency also allows us to significantly reduce user-side cost per generation.
Workflow friendly. Making sure 3D models are ready to use in downstream applications is critical. We support output formats such as glb, usdz and fbx. We are also launching a Unity plugin next week, with Blender & UE plugins coming later. We are also planning to add an option for polycount control, that allows you to reduce the polycount in the web app.
High-quality textures. Meshy-1 delivers a breakthrough in texture quality.
- 4K resolution. Resolution matters, and Meshy-1 textures are crisply sharp.
- PBR channels. Physically Based Rendering (PBR) has become paramount in games and films, and Meshy-1 outputs metallic, roughness, and normal maps for physical realism.
- Multiple material support for Text to Texture. When you are generating textures for an existing 3D model, it's often the case your model has multiple sets of UVs and multiple groups of texture maps. Our text-to-texture mode supports such cases well.
Style control. In Meshy-1's Text to 3D and Text to Texture modes, you can select from a variety of artistic styles for your generation, including Realistic, Cartoon, Anime, Comic, and more. This provides you with substantial control over the art style, beyond what textual prompts alone might allow.
How to Use It?
Meshy-1 is readily accessible both on our web app and Discord. While offering similar functionalities across platforms, there are distinct features to note:
- Discord provides unlimited free generations, though your creations are publicly visible on the generation channel.
- The Web App grants 20 free generations daily and adds additional capabilities like task queuing, PBR channels, style control, link sharing, and management of your generation workspace.
The latest Text to Texture and Image to 3D features are readily usable on both Discord and the web app. You can find the updated Text to 3D on Discord today, and it will be available on the web app in a few weeks.
So how to use these features in real world? Through early adopters we have found patterns to effective 3D generation: use Text to 3D for props (environment art), and Image to 3D for characters.
Text to 3D for props. Simply enter a text prompt and let Meshy-1 create models as per your description, ideal for generating environmental assets or "props" in games. Ensure consistent style using our style option.
Scene created by RenderMan, senior UE artist based in New York, with everything generated using Meshy-1 Text to 3D.Image to 3D for characters. Utilize a front view image, including those from Midjourney or Stable Diffusion, and Meshy-1 will elevate it into a 3D model. The Image to 3D feature ensures strong output control, creating a genuine 3D representation of your 2D input, making it a favorite among early users for character creation.
Scene by Samuel, CG artist in Tokyo, Meshy early Adoptor. All characters are generated using Meshy-1 Image to 3D and then animated using Mixamo.How to select suitable images? Prefer front views (with the camera positioned directly in front of the character) and a clean background.

Retexture models using Text to Texture. Using our battle-tested Text to Texture mode, you can easily create or repleace textures of exsiting models, especially those generated by AI.
Beyond the Horizon

Our aim is to establish Meshy as the premier platform in 3D GenAI. While Meshy-1 marks a significant stride forward, it is by no means the final chapter. In fact, the technological advancement of GenAI for 3D lags behind that of GenAI for text or images. This is because 3D introduces more dimensions and complexities. Hence it takes time for 3D GenAI products to really meet production quality.
Besides optimizing Meshy-1 outputs, we're exploring the following avenues for our product roadmap, guided by our user feedback and learning,
Improved mesh quality. The current limitations of generative AI, such as high polycounts (usually 100K+), poor UV unwrapping quality, and the lack of quad faces, have restricted its prowess in generating production-ready assets. Addressing these constraints is vital, especially considering the industry's preference for quad faces in animation and low polycount models for mobile gaming.
Conversational iterations. As users gravitate away from traditional 3D modeling software like Maya and 3Ds Max, they desire increased control over AI-generated outputs. It's helpful to empower users with iterative refinement capabilities, reminiscent of ChatGPT-style multi-round interactions.
Enhanced control. For instance, users wish to create 3D models by generating them from multiple 2D perspectives, such as front, side, and back views. For image to 3d, we believe multi-view generation is an important direction to go.
Outputs with style consistency. Consistency in stylistic rendering is a recurrent user demand, emphasizing the need for models to adhere to a designated visual theme.
Finally, a heartfelt appreciation and kudos to the entire Meshy AI team. Our current success is a testament to everyone's unwavering commitment and efforts. As we look forward, the horizon is promising, and I have no doubt that together we'll continue to innovate and excel. Stay engaged, as we're on the cusp of unveiling something even more remarkable!
[1]Prior to embarking on the Meshy journey, I completed my Ph.D. in CG & AI at MIT, contributing to research published at renowned conferences like SIGGRAPH and ICLR. After finishing my doctoral studies in 3.5 years, I've spent the subsequent 2.5 years as a startup founder, allowing me to bridge my academic knowledge with the practical aspects of building real-world products, all while continuing to learn and grow in this dynamic field.
[2]Why us? The Meshy team is comprised of experts from esteemed institutions and companies like MIT, Harvard, NVIDIA, Microsoft, Google, and Meta, with profound knowledge in computer graphics, AI, GPUs, differentiable programming, and cloud computing. We've previously built developer- and user-centric products received by our user base. These experiences provide a solid foundation for crafting a 3D generative AI product.
[3]We launched a tool called Meshy Texturer in March 2023, but now Meshy-1 is here with an upgraded Text to Texture. You can pair Meshy Texturer with our Text to 3D and Image to 3D modes, allowing you to fine-tune the textures on the AI-generated outputs.
[4]Data derived in a lab setting. During periods of high server load, wait times may exceed one minute.


