このガイドでは、Meshyという高度なAI 3Dモデル生成ツールを使用して3Dモデルを作成する方法を紹介しました。この革新的なツールは、テキストから3Dへのモデル変換を可能にし、シンプルな説明から3Dアセットを簡単に作成できます。
ステップ1: テキストから3Dワークスペースへ移動
自分のデザインを作成するためには、左のサイドバーにある「Text to 3D」タブをクリックするだけです。ここで、無料の3Dモデリングツールが活躍し、アイデアを簡単に形にすることができます。
 Dashboard
Dashboard
ステップ2: テキストプロンプトを入力
プロンプトボックスに生成したいオブジェクトを説明します。形状、色、サイズ、スタイル、その他の属性について詳細に記述してください。具体的であればあるほど、AI 3Dモデリング技術がより効果的に機能します。さらにインスピレーションが必要な場合は、初心者向けガイド「50+ Meshy Keywords to Create Amazing 3D Models」をご覧ください。
プロンプトを入力したら、「Generate」をクリックします。タスクは「My Generations」セクションに表示されます。
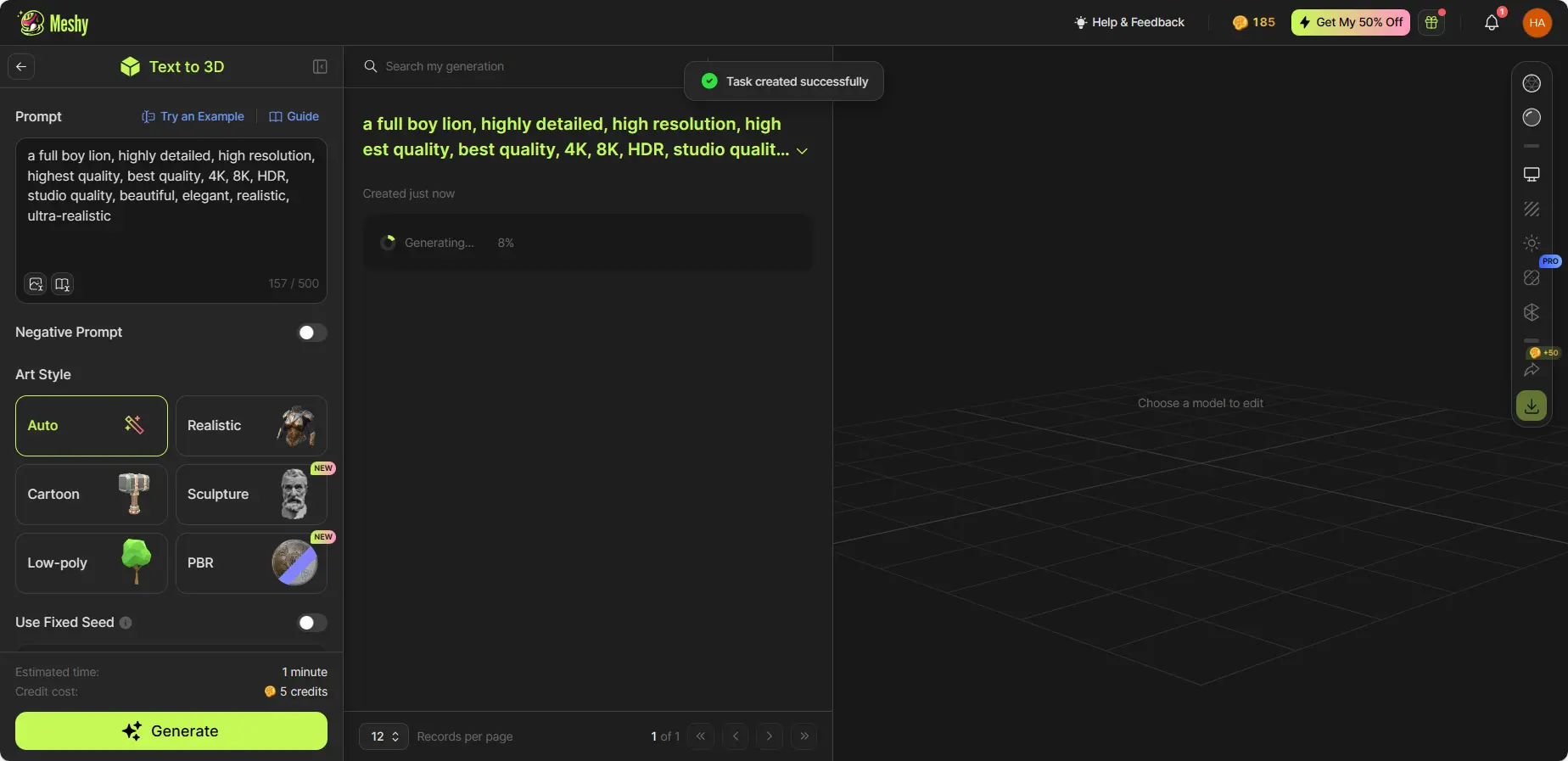 Prompt Formula: Main subject + Style details + Other details
Prompt Formula: Main subject + Style details + Other details
ステップ3: プレビューモデルを選択して洗練
Meshyはビデオ形式で4つのドラフトモデルを返します。気に入ったモデルの「Refine」をクリックしてさらに洗練します。どのモデルも満足できない場合は、「Regenerate」をクリックして新しいセットを生成します。
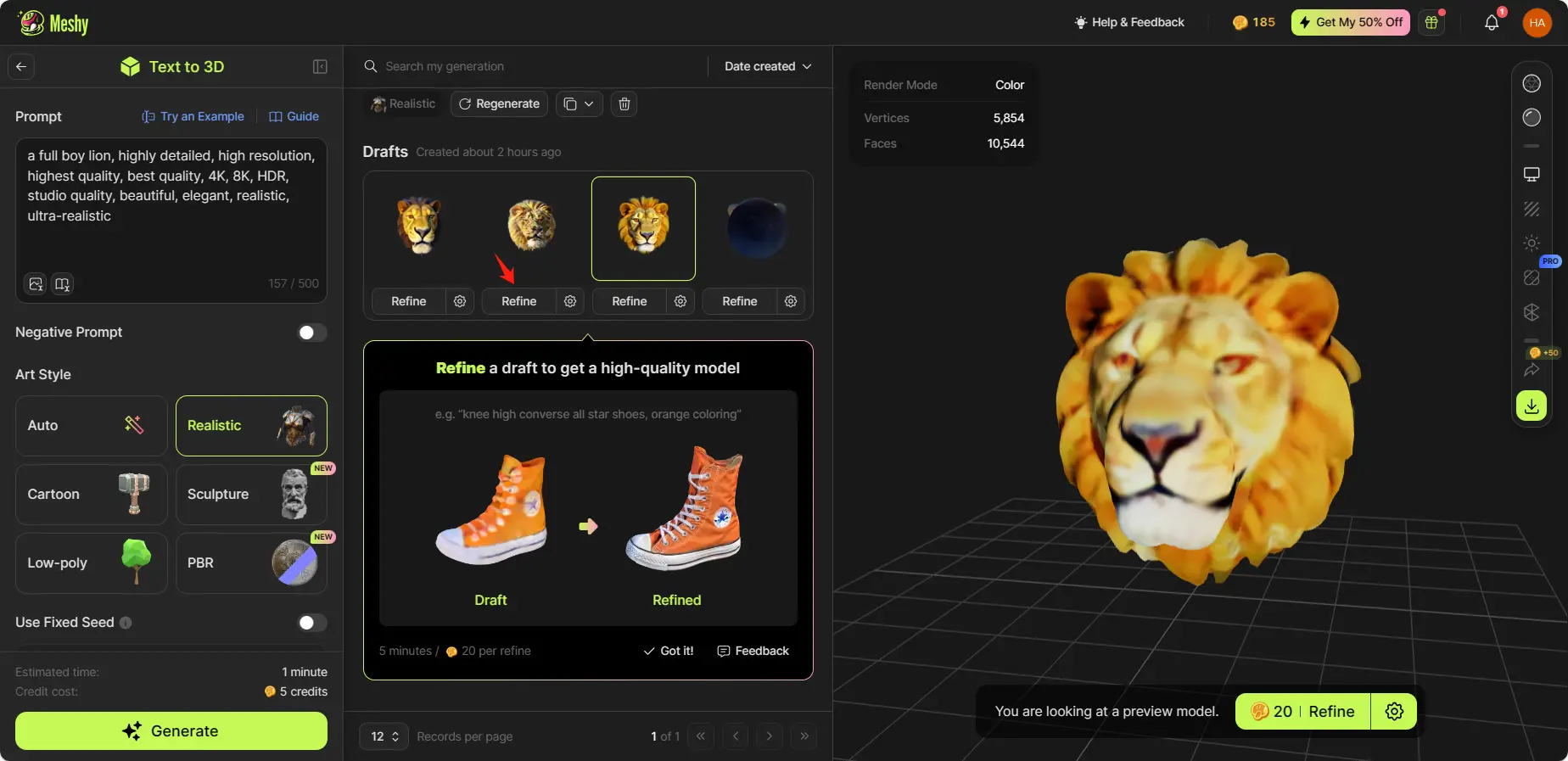 Generate process
Generate process
洗練されたモデルはプレビューの下に表示されます。複数のプレビューモデルを洗練することができます。
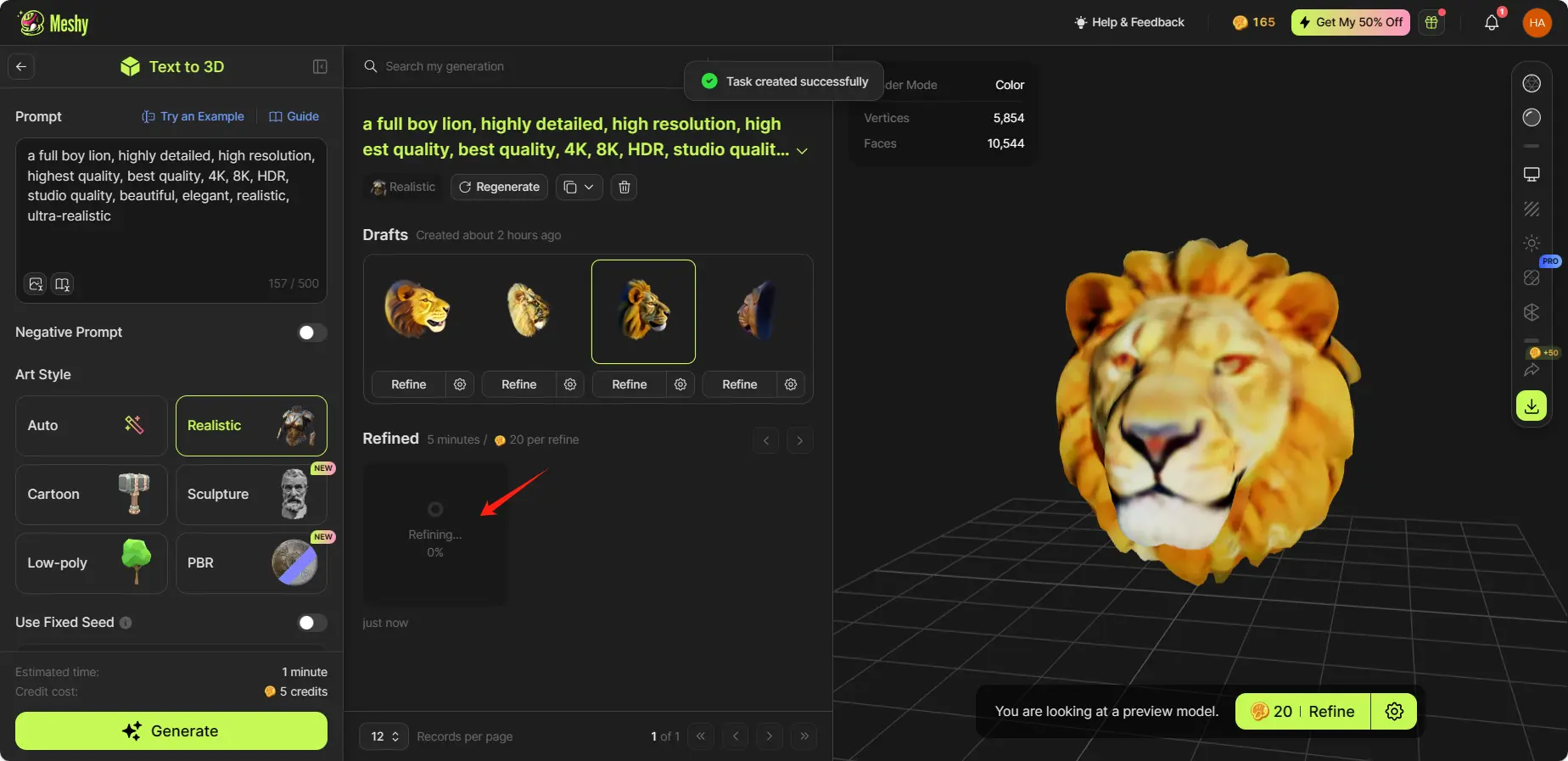 Refine process
Refine process
ステップ4: 洗練されたモデルを探索
洗練されたモデルをクリックして、3Dビューアで詳細に表示します。右側のプレビュー設定パネルを使用して、さまざまな設定を調整します。PBRシェーディングに切り替えると、HDRIの強度と回転を調整でき、テクスチャ設定ではテクスチャのメタリックと粗さを微調整できます。
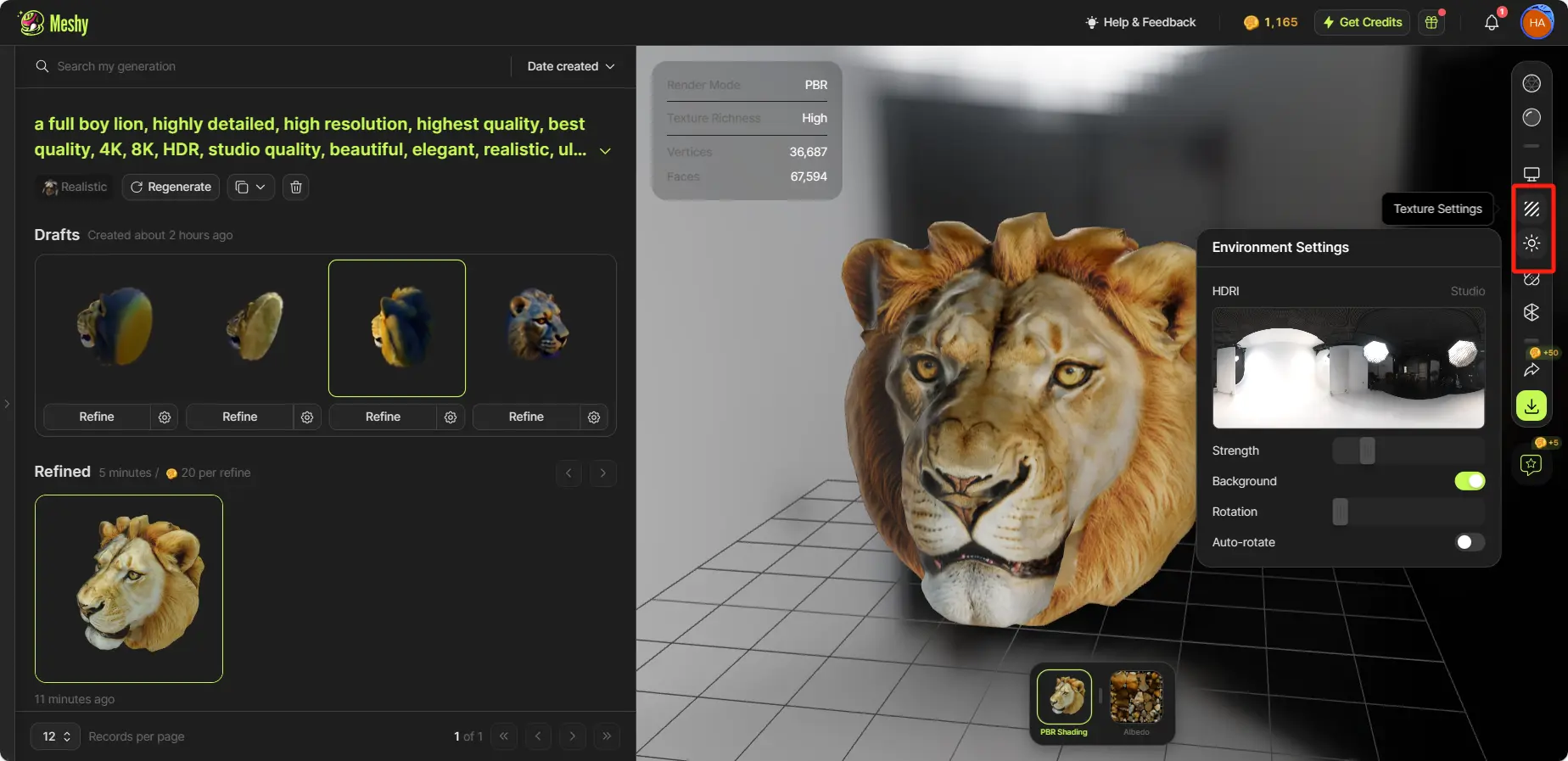 Texture Settings
Texture Settings
これらのパラメータを調整しても、モデルやテクスチャ自体のプロパティは変更されません。異なるプレビューオプションを提供するためのものです。
ステップ5: テクスチャとメッシュを編集
AIテクスチャ編集
プレミアムプランをご利用の場合、AIテクスチャ編集ツールを使用してモデルのテクスチャを再加工したり、不要な要素を削除したりできます。
AIテクスチャ編集は、テクスチャの一部を再生成するのに役立ち、スマートヒーリングはテクスチャからスポットを削除するのを支援します。
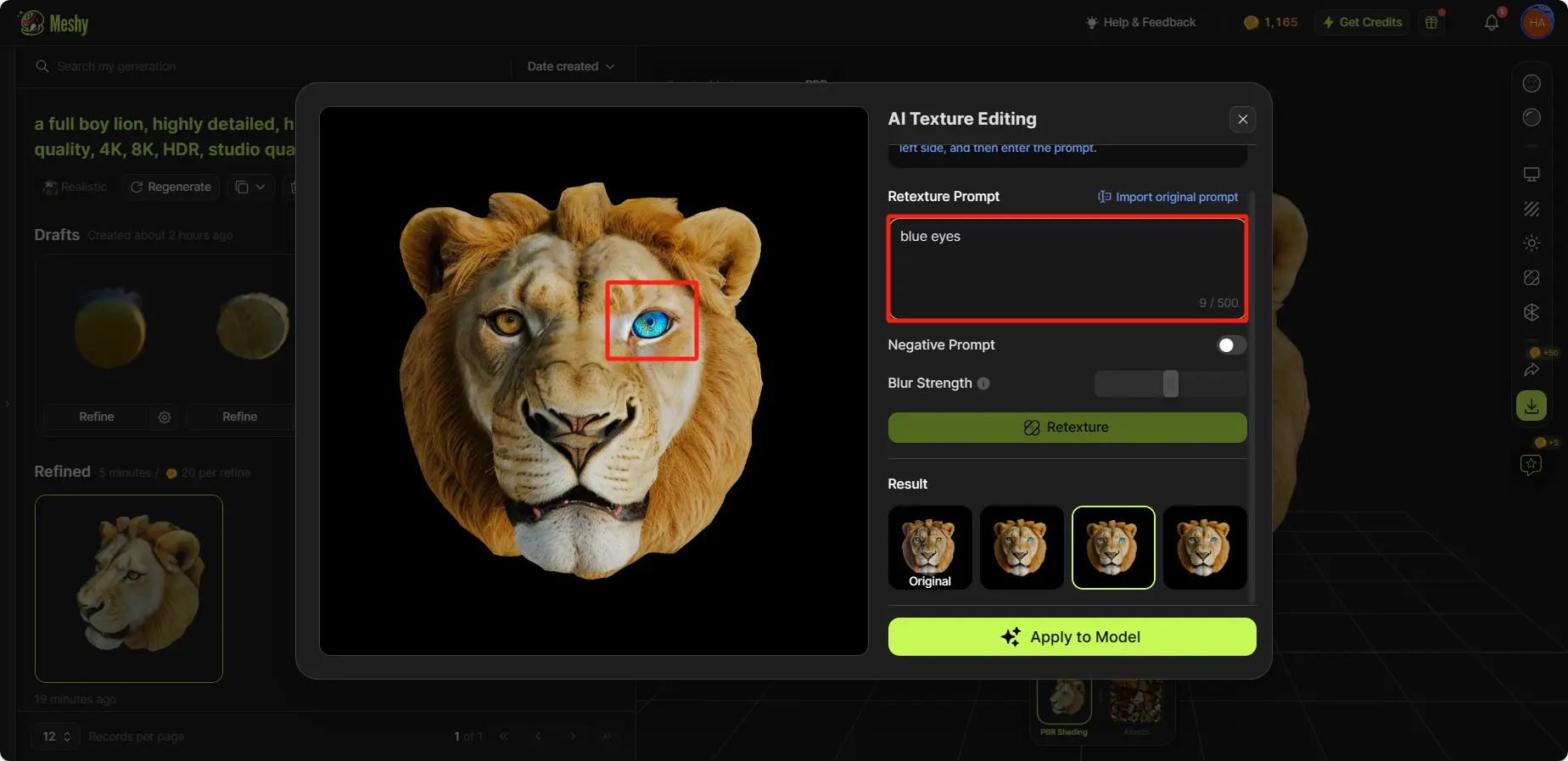 AI Texture Editing
AI Texture Editing
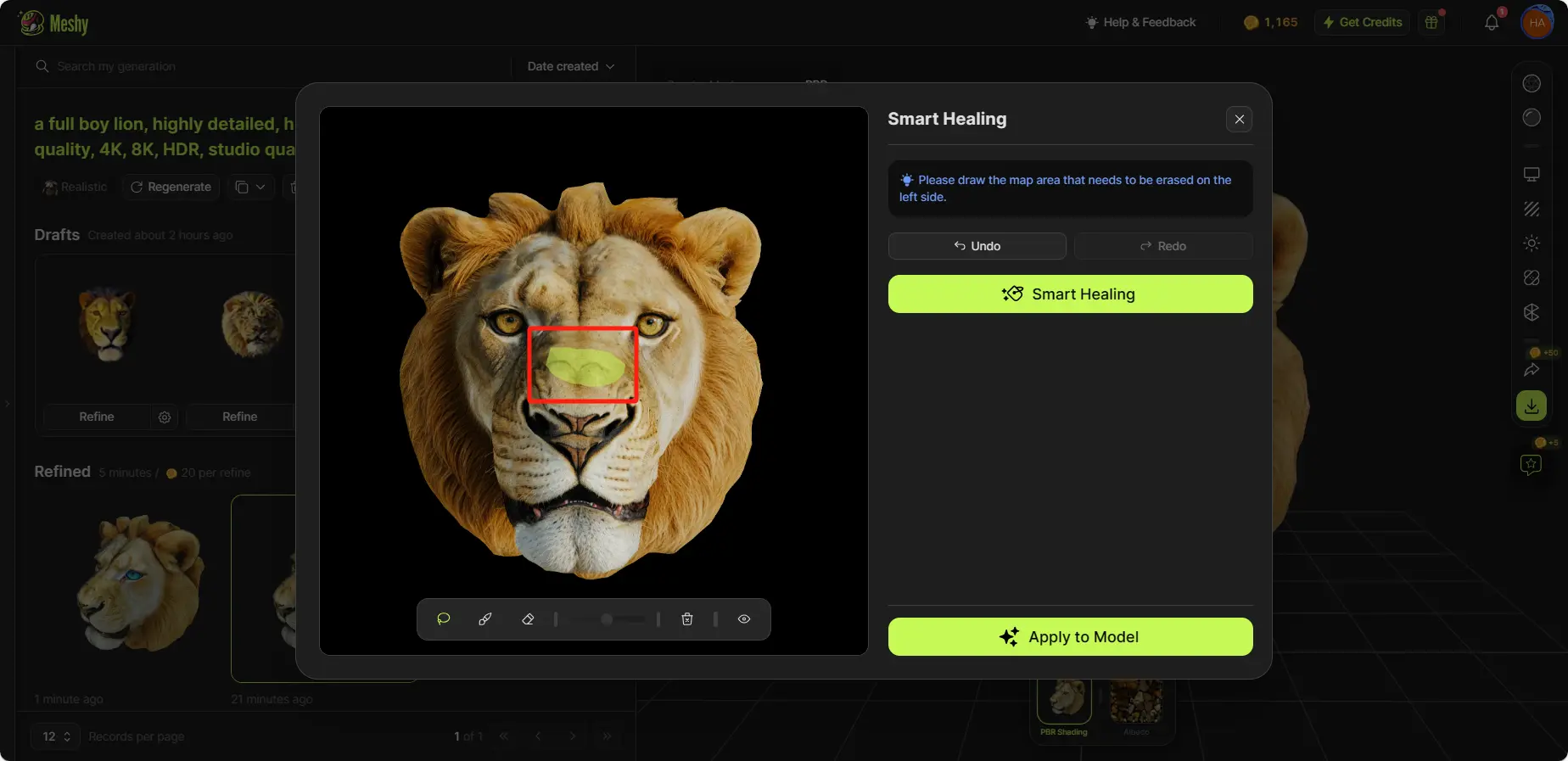 Smart Healing
Smart Healing
メッシュ設定
Meshyはポリゴン削減とモデルの四角形への変換をサポートしています。右のツールバーで「Mesh Settings」をクリックします。このプロセスは数秒で完了します。
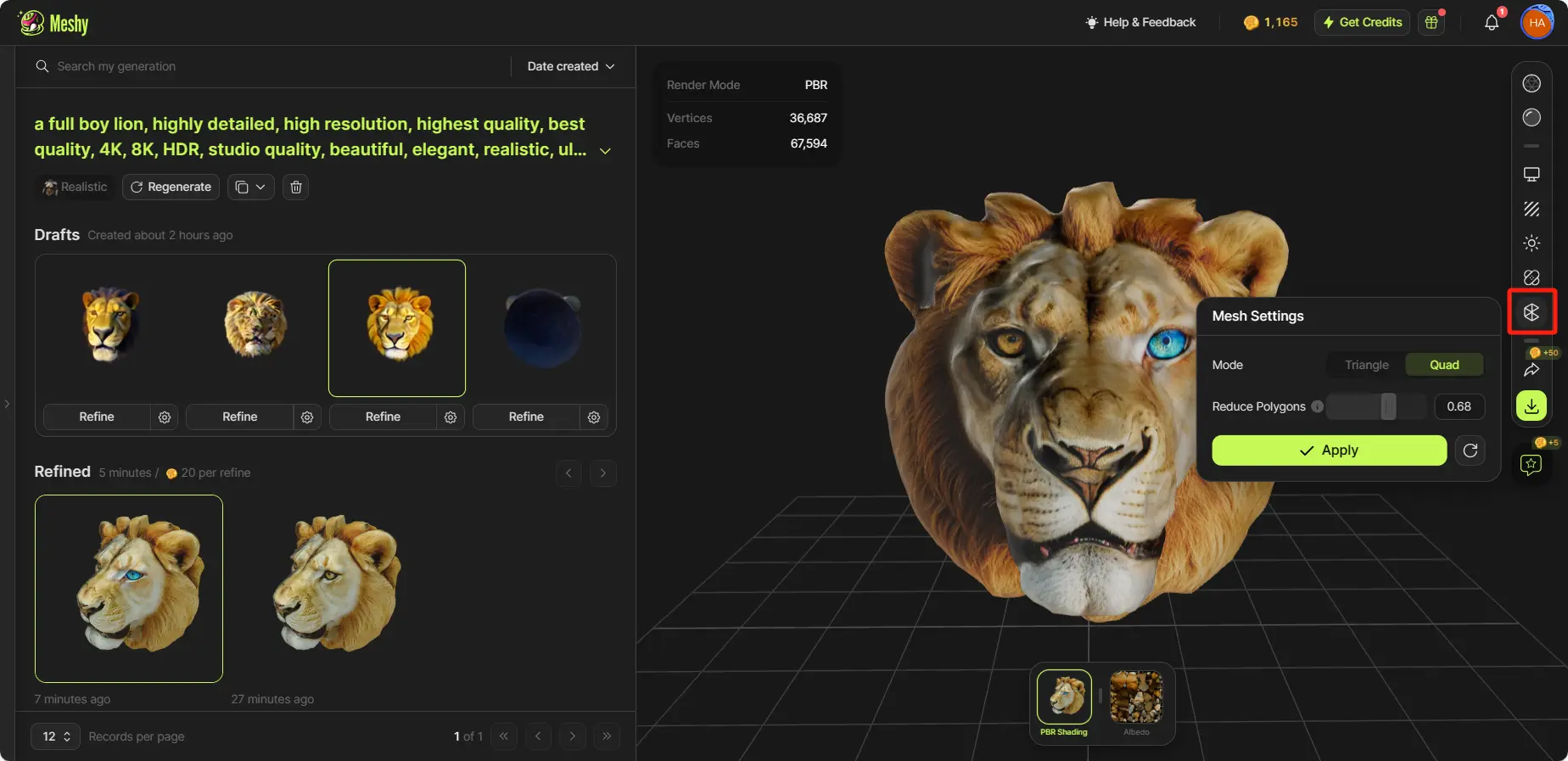 Mesh Settings
Mesh Settings
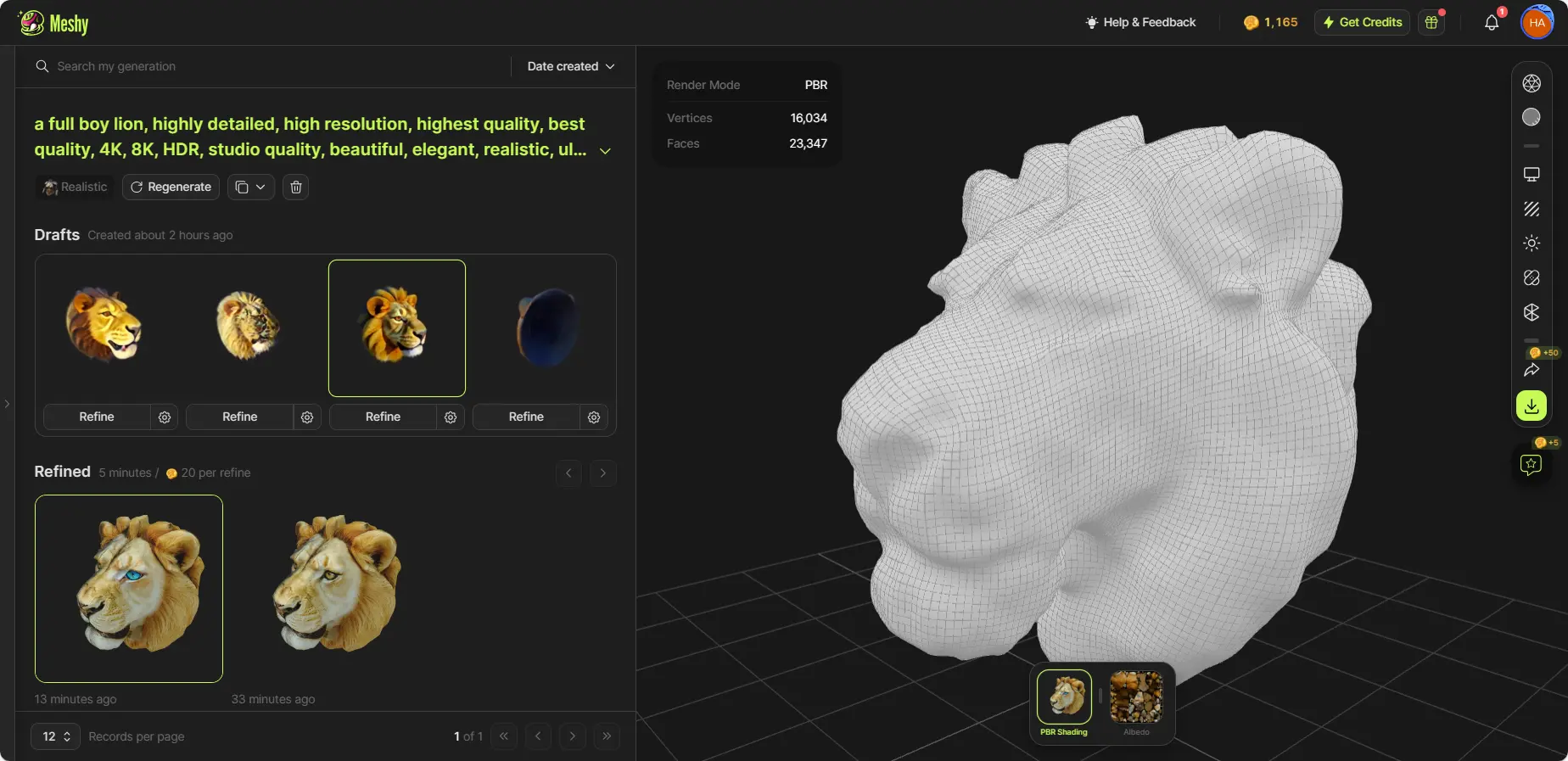 ポリゴンを減らす
ポリゴンを減らす
ステップ6: アセットをダウンロードする
右のツールバーの「ダウンロード」ボタンをクリックしてアセットをダウンロードします。サポートされている形式には、.fbx、.obj、.usdz、.glb、.stl、および .blend が含まれます。
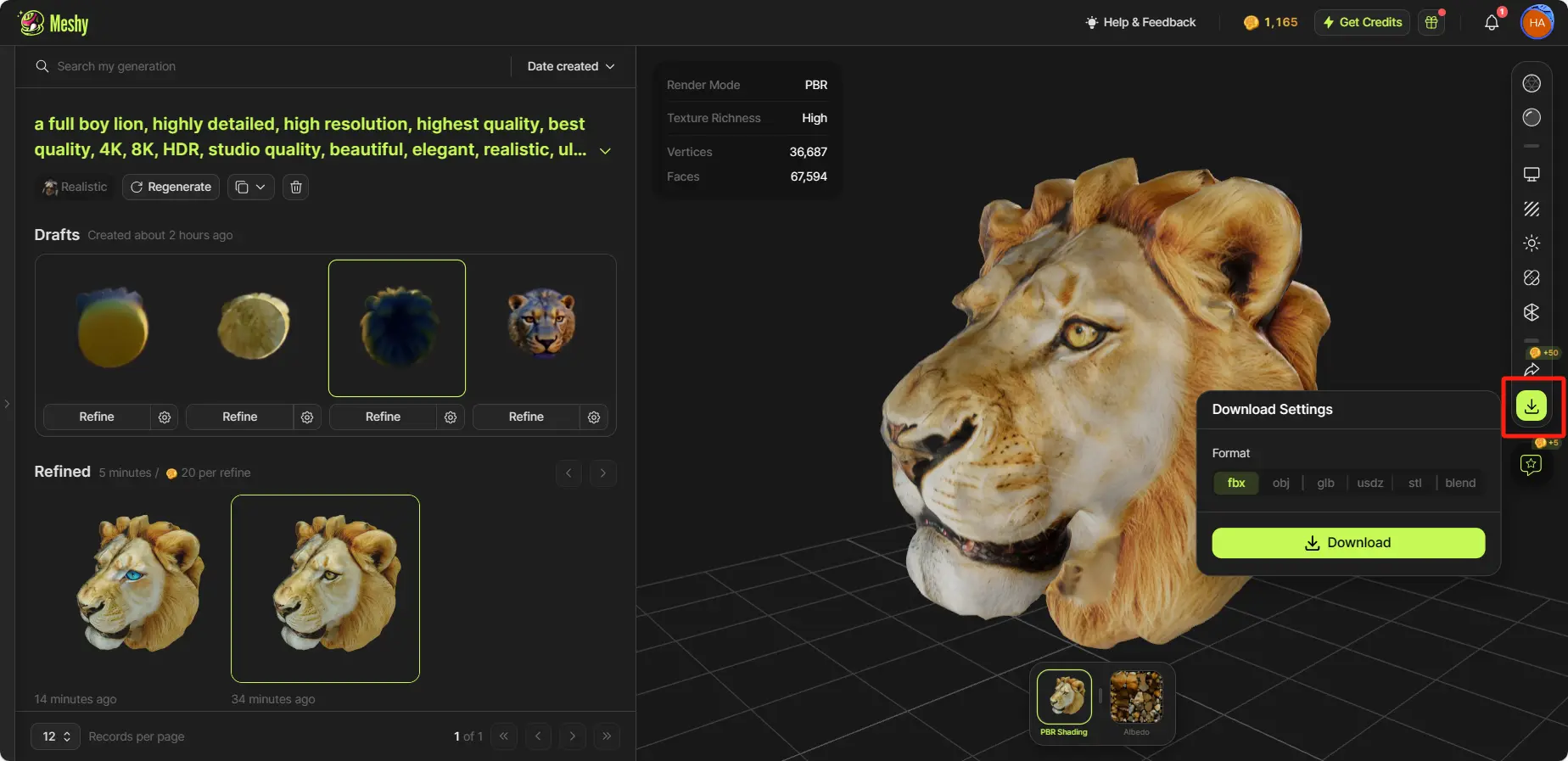 モデルをダウンロード
モデルをダウンロード
ステップ7: 作品を共有する
コミュニティや友人と作品を共有したい場合は、右のツールバーの「共有」ボタンをクリックするだけです。そこから、モデルをMeshyコミュニティに公開したり、メールやソーシャルメディアで共有したり、モデルのプレビューリンクをコピーしたり、作品のビデオプレビューをダウンロードしたりできます。
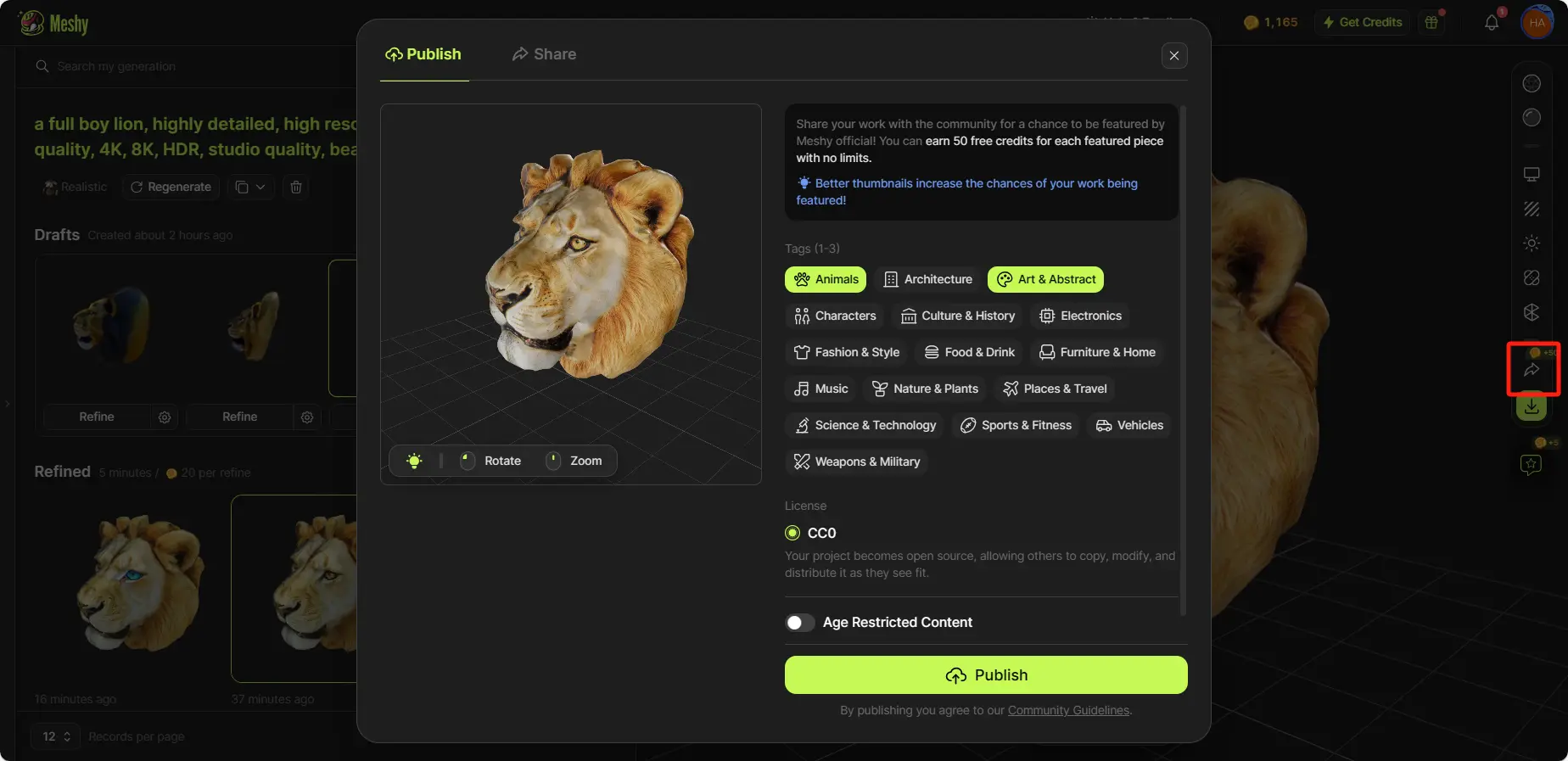 コミュニティに公開
コミュニティに公開
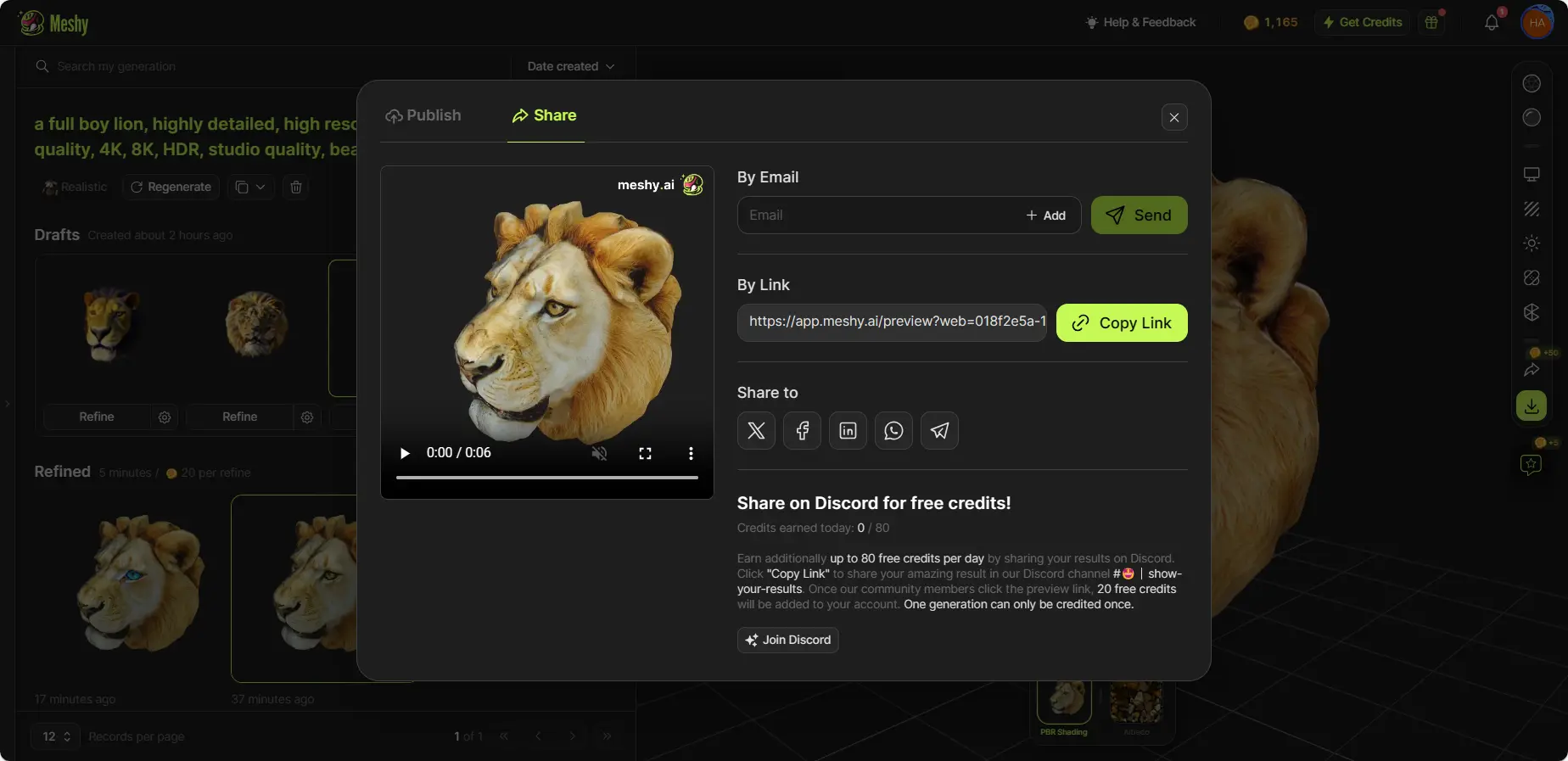 ソーシャルメディアプラットフォームで共有
ソーシャルメディアプラットフォームで共有
フォローする
Meshyについてもっと知りたい場合は、私たちのソーシャルメディアプラットフォームをチェックしてください。AI 3Dモデルジェネレーターがどのようにあなたのクリエイティブなワークフローを変革できるかを学びましょう:
- 最新のチュートリアルをお届けするために、私たちのYouTubeチャンネルを購読してください。
- ニュース、ヒント、インスピレーションを得るために、Twitterでフォローしてください。
- 他の3Dアーティストとつながるために、私たちのDiscordコミュニティに参加してください。


